A visual introduction to AI in Personalize.AI
Personalize.AI incorporates state-of-the-art production grade AI delivered at scale. Here is a deep-dive into P.AI's cutting edge modules and how they work.
Create hierarchical customer level profile graph which is updated continuously
Ensemble methods across each AI step to identify best of breed AI models
Scalable AI engine that has dedicated model calibration pipelines
Integrated MLOps and Drift Monitoring
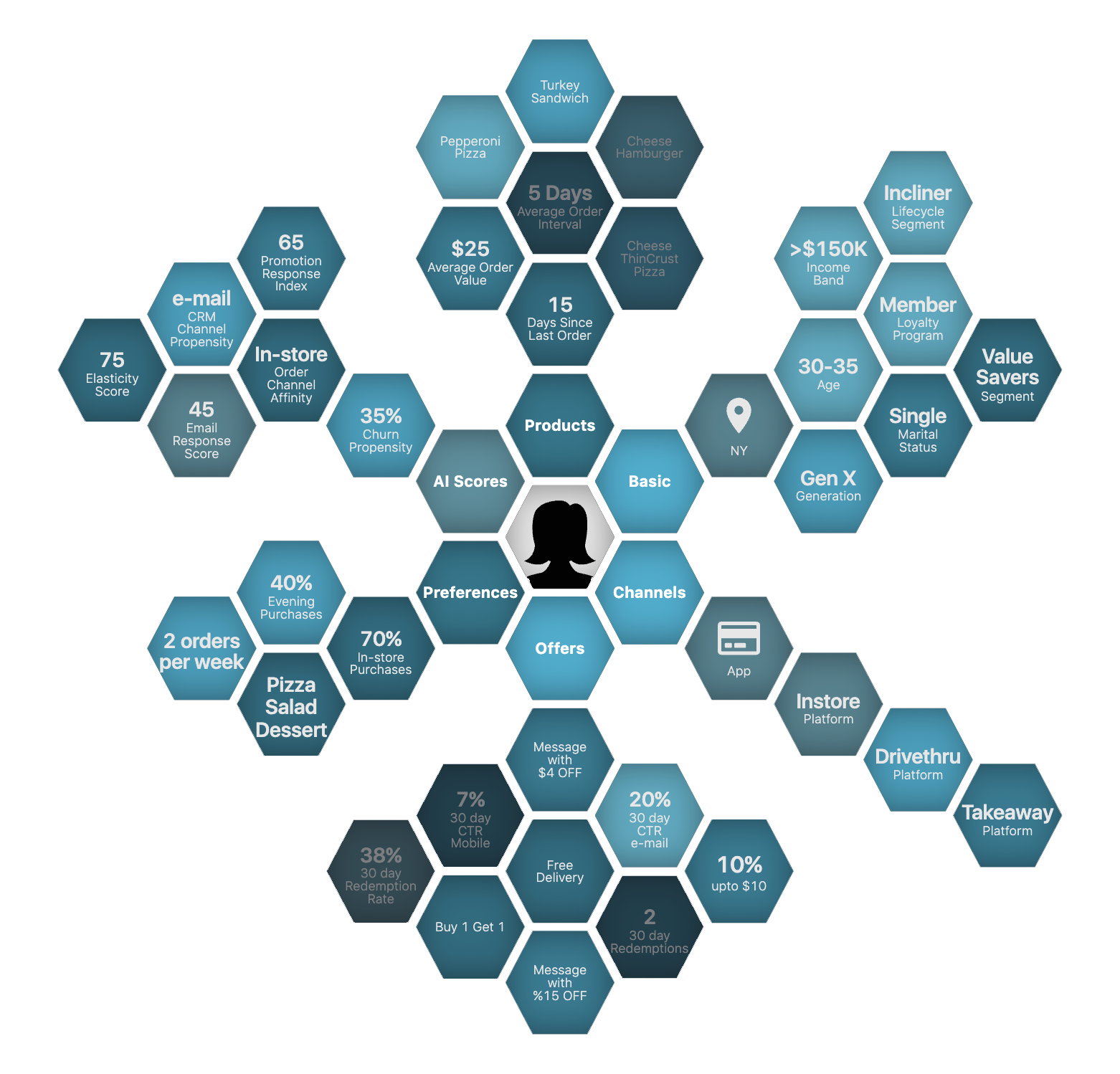
A feature is a measurable property of some data-sample. It could be a piece of text or an age of a person or reading recorded by a sensor. They can be extracted directly or can be derived from one or more data sources.
While the features act as fuel for machine learning models, they are the hardest ML artifacts to create and manage. And it may sound counterintuitive, but many features can be applicable for wide variety of use-cases. For instance, search and recommendation can use similar features, built around user-behavior.
When features are reusable, every new model deployment makes subsequent model deployment easier and eventually only small amount of feature engineering might be required for new models. P.AI's Auto-Feature Engineering capability builds features from raw data which can be leveraged by downstream AI algorithms to execute different AI algorithms.
The goal of auto feature engineering is to improve the accuracy and efficiency of machine learning models by creating new features that capture the underlying structure and patterns of the data. Auto feature engineering algorithms typically work by exploring different combinations of existing features and applying transformations or mathematical operations to create new features. These new features are then evaluated and selected based on their relevance to the target variable and their ability to improve the performance of the machine learning model. Auto feature engineering has several advantages over manual feature engineering, including its ability to handle high-dimensional and complex data, its ability to create new features that are difficult for humans to identify, and its ability to reduce the time and effort required for feature engineering.
Hierarchical voronoi tesselation is a classification algorithm that layers different customer segments to form nano cohorts which can be used for precise targeting. To begin with, the algorithm builds a customer journey and identifies where customer is based on his recent engagement and frequency of interaction with the brand. Existing business segments are mapped to these stages. These overlays are used to divide the customer base recursively into smaller cohorts. The recursion terminates when the cells either contain a single data point or a stop criterion is reached. In this case, the stop criterion is set to when the cell error exceeds the quantization threshold.
In HVT, the Voronoi cells are arranged in a hierarchical structure, with each level of the hierarchy representing a coarser partitioning of the space. The top level of the hierarchy consists of a single cell that covers the entire space, and each subsequent level of the hierarchy subdivides the cells of the previous level into smaller cells.
The HVT algorithm works by recursively subdividing the Voronoi cells of each level of the hierarchy based on the proximity of the Voronoi generators. At each level of the hierarchy, the Voronoi cells are subdivided into smaller cells, until a stopping criterion is reached, such as a minimum cell size or a maximum number of levels.
HVT has several advantages, including its ability to efficiently handle large datasets, its ability to adapt to the density and distribution of the Voronoi generators, and its ability to support efficient queries of the Voronoi diagram, such as nearest neighbor searches.
Not all customers are alike when it comes to spending marketing dollars. In fact, a good number of customers do not need discounted offers and even those who do, like variations such as "Buy One Get One" offer. Others like "Free Delivery" or "$ Off".
There are customers who seek discounts in every purchase and then some who like to feel special occasionally, a birthday or an anniversary.
Personalize.AI has a portfolio of recommendation system which gives personalized recommendation to all the customers based on their current viewing and previous purchases. It must be able to take into consideration the implicit patterns in transactions including the customer attributes, item attributes and current trends. It generates real time recommendations for every and any customer-item pair, and generates fail-safe recommendations for every customer.
P.AI breaks this problem into an elasticity and spend optimization problem. All customers are elastic, but some customers are more elastic than rest. It is precisely this difference in customer elasticity that the P.AI personalization engine exploits. It helps to think of elasticity as a single dimension attribute of a customer but it’s not, remember customers are diverse, therefore a customer may like discounts on beverages, but they are happy paying the full price for their salads. A highly elastic customer will respond favorably to promotions.
If targeted with the right discount offer at the right time, one or multiple of the following events happen – either their order size goes up (AOV), they purchase more frequently (AOI goes down) or all in all they spend more on a product if they feel special (CLV). These are the customers that any marketeer should never miss reaching out to.
Also, likewise a good majority of customers are not elastic, these are customers who have a fixed purchase cycle or frequency, they are not impacted much by exclusive promotions or deals. They buy your product because they like what they are getting at its current price, you don’t want to overspend on retaining these customers. A marketing plan for these customers should focus on their existing preferences and help them discover value.
We use choice modelling to get demand curves and then compute customer scores. We need choice data, but in cases of sparse data such as only transaction data being available, we don’t get any details of the items seen by the customer before buying any item. We use recommendations as the choice alternatives for each customer x item combination in transactional data. Using mixed logit model on the created choice data. we get the values for demand curves at customer x product category level (probabilities at different price points). Since most of the demand curves were either linear or decaying type, so we fit polynomial model with degree 2 to get the coefficients (saved as customer model data). We take the last N interactions for each customer - product category, get quantity weighted point elasticities to get customer score for each category in his/her basket.
Meta-learners, also known as meta-learning algorithms, are a class of machine learning algorithms that aim to learn how to learn. That is, they learn to adapt to new tasks or problem domains quickly and effectively by leveraging knowledge acquired from previous tasks. Meta-learners typically consist of two components: a learner and a meta-learner. The learner is a model that is trained on a specific task, and the meta-learner is a model that learns to optimize the learner's performance across multiple tasks.
Meta-learners allow us to calculate impact of giving out an offer (promotion, discount, voucher etc.) on customer’s engagement and spends. The increase in engagement, i.e. lift generated by a marketing intervention in a customer’s revenue is often not directly observed i.e. the counterfactual scenario is not available for any customer, either a customer receives an offer or doesn’t.
X-Learner consists of two main components: a propensity model and a response model. The propensity model estimates the probability of a user selecting a recommended item, given their user and item features and the recommendation algorithm used. The response model estimates the user's response to the recommended item, given their user and item features.
X-Learner uses both models to estimate the expected outcome of each recommendation algorithm for each user, and then selects the best algorithm for each user based on their expected outcome. This allows X-Learner to adapt to different users and make personalized recommendations that are tailored to each user's individual preferences.
One of the key advantages of X-Learner is its ability to handle heterogeneous treatment effects, which can be particularly important in recommendation scenarios where the same recommendation algorithm may not work equally well for all users.
HinSAGE (Heterogeneous Information Network-based Scalable Graph Embedding) is a graph neural network model used for learning node representations in heterogeneous information networks (HINs). HINs are graphs that represent different types of nodes and edges, such as users, products, and reviews in an e-commerce platform.
The HinSAGE model learns node embeddings by capturing the structural and semantic information of the HIN. The model consists of two main components: the aggregator and the encoder. The aggregator function aggregates the information from a node's neighborhood, and the encoder function maps the aggregated information to a lower-dimensional space, where it is used to represent the node as a vector.
HinSAGE has been shown to outperform other state-of-the-art graph embedding methods on various downstream tasks, such as node classification and link prediction, especially in large-scale HINs. The model is therefore useful for a wide range of applications, such as recommender systems, social network analysis, and bioinformatics.
PinSAGE (Graph Convolutional Neural Networks with Personalized Aggregation) is a graph neural network model that is designed for learning node representations in large-scale, personalized recommendation systems.
In PinSAGE, the model is trained to predict the likelihood of a user interacting with a particular item. The model takes into account the user's historical interactions and the features of the items to create personalized embeddings for both the user and the item. The personalized embeddings are then used to predict the probability of the user interacting with the item.
PinSAGE uses a two-level aggregation approach, where the model first aggregates information from the item's local neighborhood to create item embeddings, and then aggregates information from the user's historical interactions to create personalized embeddings. The model also uses negative sampling to improve the quality of the learned embeddings.
One of the key advantages of PinSAGE is its ability to handle large-scale recommendation systems with millions of items and users. PinSAGE achieves this by using scalable graph neural network techniques that can efficiently learn personalized embeddings for each user and item.
Another advantage of PinSAGE is its ability to handle different types of data, such as textual and visual features of items, in addition to user-item interaction data. This makes PinSAGE well-suited for recommendation scenarios where there is rich and heterogeneous data available.
The basic idea behind matrix factorization is to factorize a user-item interaction matrix into two lower-dimensional matrices, one for users and one for items. These lower-dimensional matrices, known as embeddings, can be used to represent users and items as vectors in a lower-dimensional space.
The user-item interaction matrix contains information about how users have interacted with items in the past, such as ratings or purchases. By factorizing this matrix, matrix factorization is able to learn latent features of users and items that are not directly observed but are still relevant for predicting user preferences.
Once the embeddings are learned, the model can use them to predict the likelihood of a user interacting with an item that they have not yet interacted with. This can be done by computing the dot product between the user and item embeddings, which gives a measure of their similarity.
The role of experimentation is to empower decision-making by providing credible insights into the consequences of decisions. Effective experimentation however can be time-consuming and complex, and quite often difficult to scale.
- Design complex & robust experiments that are designed with statistical confidence
- Monitor and assess experiments with detailed insights into what worked and what did not
- Leverage Generative AI/OpenAI to create and scale content variations
One common technique for experimentation is A/B testing, which involves randomly assigning individuals to one of two groups: a control group that receives the current design or treatment, and a treatment group that receives the new design or treatment. The groups are then compared to determine if the new design or treatment has a statistically significant effect on the outcome of interest. A/B testing can be used in a variety of contexts, including website design, marketing campaigns, and product development.
To perform A/B testing for design, a sample of users is randomly assigned to two groups that receive different versions of the design. The groups are then compared on metrics such as engagement, conversion rates, or user satisfaction. To perform A/B testing for measurement, a sample of users is randomly assigned to two groups that receive different levels of the variable being measured (e.g. price, duration, or frequency). The groups are then compared on metrics such as revenue, usage, or retention.
We use customer longitudinal journeys and along with journeys of thousands of similar customers to learn what are their latent preferences. Measuring elasticity of customers is a difficult problem, primary challenge we face is that we do not observe elasticity of customers in real world, which means that it’s not available to us in a data warehouse.
What’s available in the data is historical marketing campaigns– a treasure trove of experiments that a business has run in the past which is one amongst many such signals that P.AI optimization engine leverages. Combined with the journeys we prepared earlier we’re able to extrapolate and get hidden preferences of our customers.
Machine learning is extremely good at learning patterns. By re-framing the customer elasticity problem as a prediction problem, it is able to learn and generalize customer attributes which makes it possible for us to tailor marketing according to what works best for a customer.
Generative AI has the potential to revolutionize marketing by enabling businesses to create highly personalized and engaging content at scale. Generative AI refers to a class of machine learning algorithms that can generate new content, such as text, images, or videos, based on a set of input variables or patterns. By training these algorithms on large datasets of customer data, businesses can generate content that is tailored to each individual customer's preferences and behaviors.
One of the most promising applications of generative AI in marketing is content generation. By analyzing customer data, such as search history, purchase behavior, and social media activity, generative AI algorithms can create personalized product recommendations, social media posts, email newsletters, and other types of content that are more likely to resonate with customers. This can lead to higher engagement rates, increased conversions, and improved customer loyalty.
Generative AI can also be used to create new content, such as product descriptions, headlines, and ad copy, that is optimized for specific audiences and search terms.